Mingsheng Li
AI Researcher @ Qwen Team, Alibaba Group
Fudan University
I am currently an AI researcher at the Qwen Team, Alibaba Group. Before that, I graduated from Fudan University under the supervision of Prof. Tao Chen. Previously, I have had the wonderful experience of working with Dr. Hongyuan Zhu from A*STAR, Dr. Gang Yu, Dr. Chi Zhang, Dr. Xin Chen from Tencent, and Dr. Bo Zhang from Shanghai AI Lab.
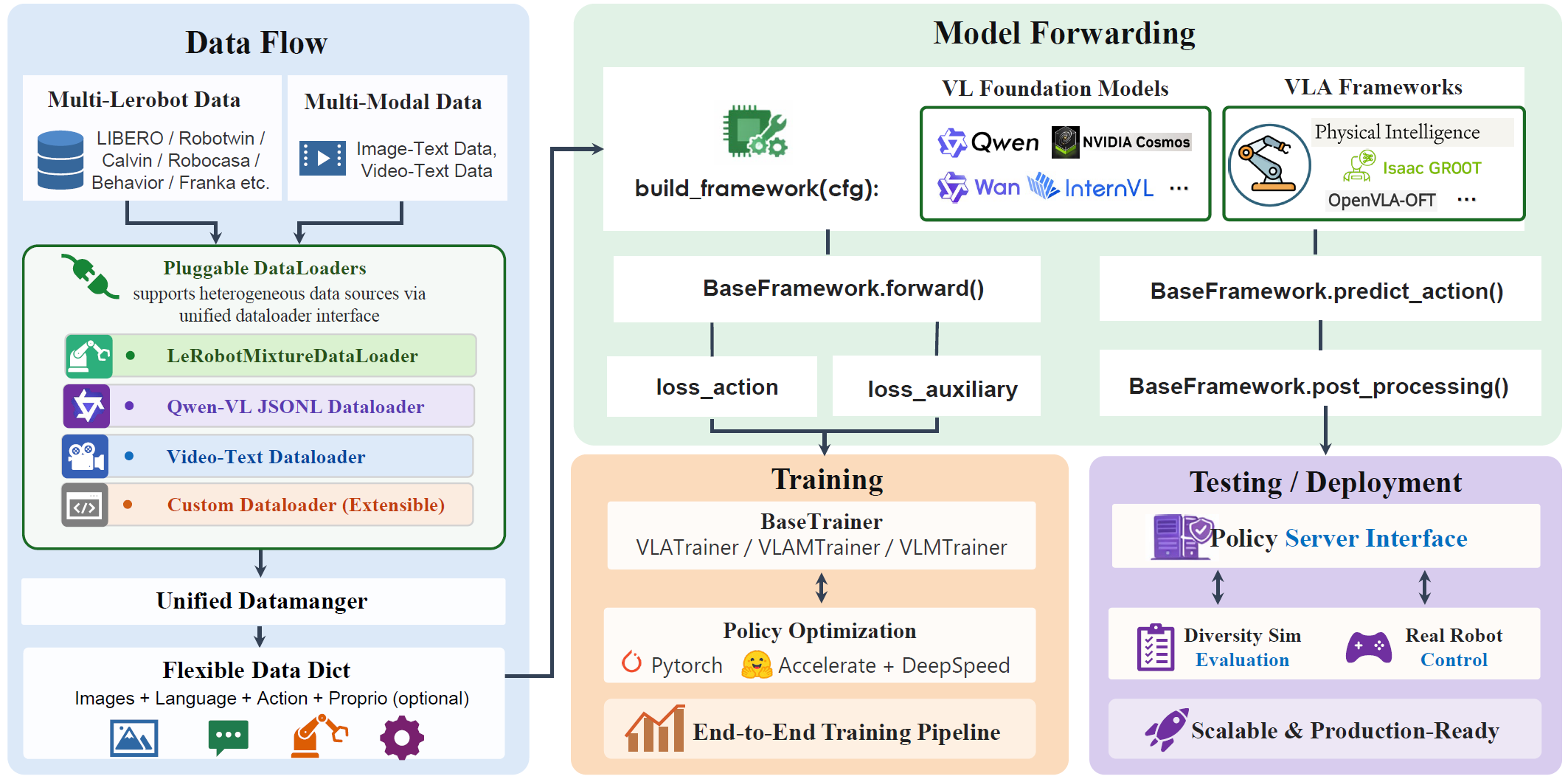
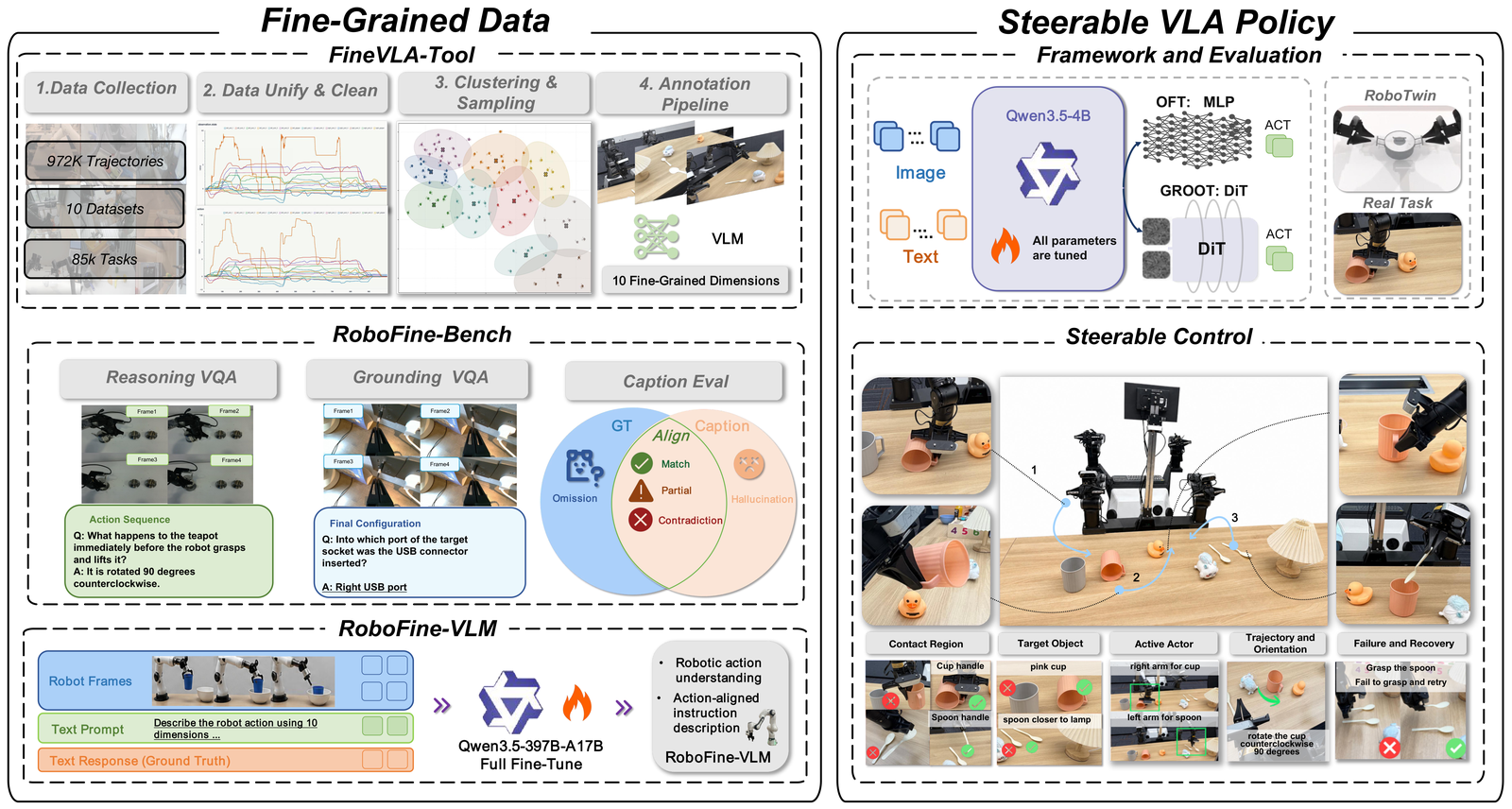
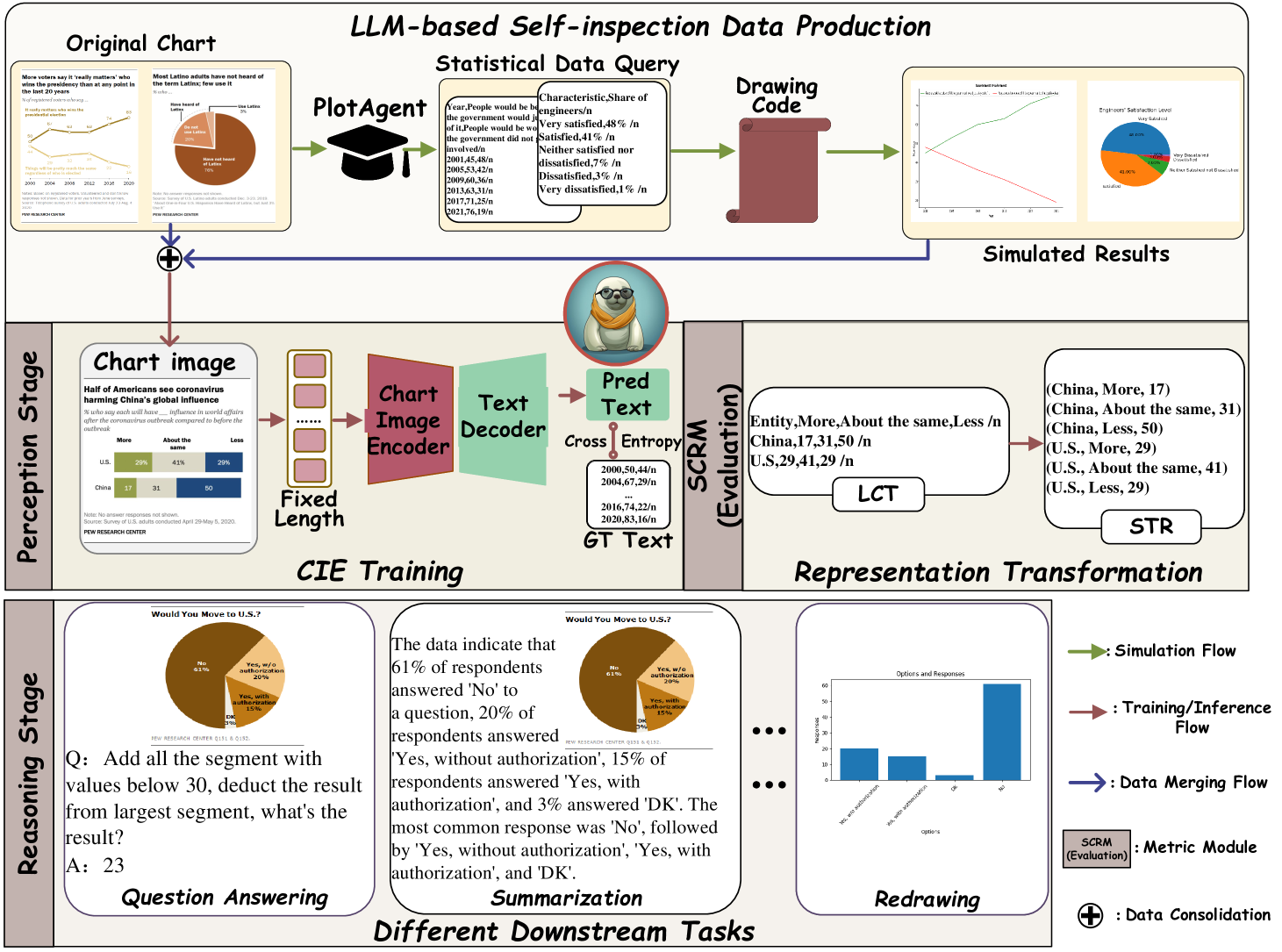
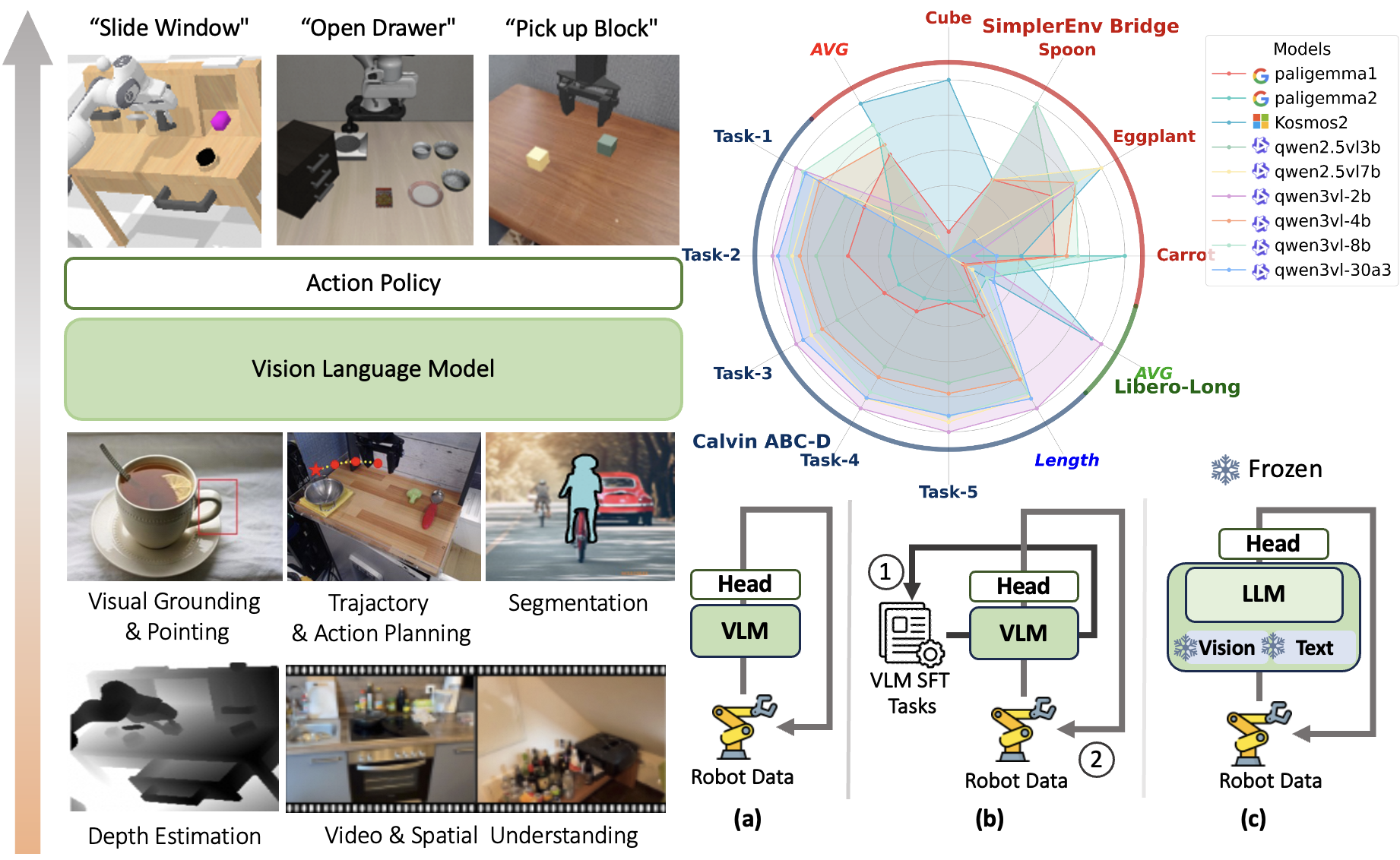
My current work and research focus on Large Vision-Language Models, Multi-agent System, Generative AI, and Embodied AI.